


Free
Trial
Use Cases
From MRZ data to Vehicle Identification Numbers, We’ll Read Them All
Text is everywhere. Learn how you can identify and extract this data to automate and enhance your workflow.
- MRZ Passports and ID Cards
- Lot No. on Drug Bottles in Healthcare
- Parcel Labels in Transport and Logistics
- Automatic Data Extraction
- Inventory and Warehouse Management
- VIN Scanning (beta release)
- Retail (beta release)
- Parts Tracking and Maintenance (beta release)
- Voucher Code Scanning (beta release)
- Checks in Banking (beta release)

MRZ Passports and ID Cards
Smart devices equipped with OCR software and technology help airports and airline employees to scan machine-readable ID cards and passports easily and instantly. With mobile devices equipped with OCR capability, employees can verify IDs anywhere in the airport. Passengers can scan their passports while checking-in online, thereby eliminating errors when entering the data and responding to alerts such as one for an out-of-date passport.
Try online demo >
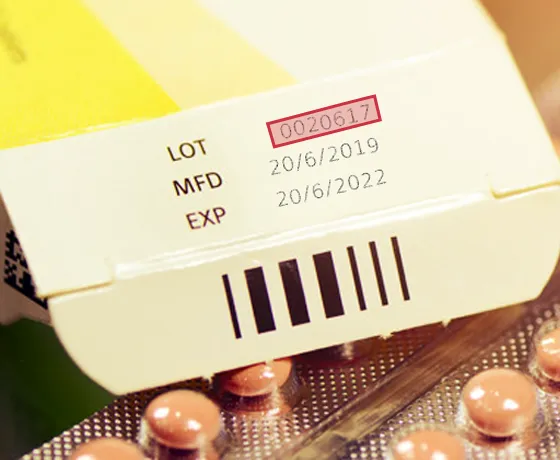
Lot No. on Drug Bottles in Healthcare
Incorporating data capture and text recognition technologies into healthcare software adds remarkable value to their applications. As an example, for pharmaceutical products that do not have data encoded within a barcode, OCR helps by instantly scanning ref or lot numbers. Staff ID badges do not need to have barcodes on them because the text printed on the badges (name, number, etc.) can be scanned for identity verification.
Parcel Labels in Transport and Logistics
OCR technology helps in reducing the errors, energy, and time associated with manual data entry processes in the transport and logistics industries. With an OCR solution, it becomes easier to read optical marks, text, and laser print, which can then index documents with data contained within the document and dispatch system. When a barcode on a parcel or package is damaged and cannot be scanned, OCR software helps by reading the accompanying text instead. Advanced OCR software can scan multiple lines of text in a single scan on a smart device.


Automatic Data Extraction
Businesses that have high volume scanning and document inflow can benefit by having a method to quickly search through volumes of content with the help of OCR. Automatic data extraction with OCR increases productivity by facilitating fast and accurate data retrieval. Users can search for documents by typing names, addresses, numbers, or unique codes, etc. Moreover, automated sorting makes the entire process more streamlined and manageable.
Inventory and Warehouse Management
With OCR, warehouse crew and staff can capture content that isn’t necessarily barcoded. Even if the barcodes are damaged, every item of inventory can be easily scanned with the help of the accompanying text to make sure that everything is in its place and to determine which items need to be restocked. Warehouse staff also make use of pallet ID labels, also known as box labels to make sure that the products are stored at the correct location in the warehouse.


VIN Scanning (beta release)
Text recognition and OCR technology are imperative in the automotive industry. Automotive industry professionals use Vehicle Identification Numbers (VINs) to identify vehicles. With the help of an image OCR SDK such as Dynamsoft Label Recognizer, users can identify vehicles anywhere, anytime by scanning VINs. Advanced text recognition solutions allow scanning VIN codes at a very high speed, that too at different angles and distances.

Retail (beta release)
Incorrect price labels on shelves can affect a store in many ways. It may affect the customer service as a buyer may select the wrong product at a wrong price due to the inaccurate price label.
In retail, OCR text recognition ensures accurate price label recognition. Multiple price labels can be easily scanned at once, reducing chances of errors. Even when a barcode is damaged, the store employees can make use of the label recognition feature on their mobile phones to perform price verification.

Parts Tracking and Maintenance (beta release)
OCR software helps maintenance operators to easily track and find different parts in a warehouse. Smart device scanning solutions equipped with OCR software can easily replace dedicated scanning hardware that contributes to reducing the total cost of ownership. Employees can scan text and barcodes on different parts, saving time in the process and decreasing the chances of errors in tracking a large number of parts. When video cameras and OCR software are combined, they can capture difficult-to-read information such as serial numbers on parts in the automotive industry. This further ensures that parts are correctly labeled and nothing is lost.

Voucher Code Scanning (beta release)
With the help of text recognition technology, companies can enable their customers to scan voucher codes on the back of gift cards using their mobile phones. To make this happen, companies need to integrate serial number scanning into an app or website. Because vouchers benefit customers in many ways, this will be a good way to promote engagement with the company.

Checks in Banking (beta release)
Accurate data capture helps to simplify banking processes, making them more efficient and faster. A recent OCR innovation allows customers to easily scan and deposit checks from their mobile phones. Every part of the check is processed, including the signature, the account number, and the amount. Numbers on checks are printed with a special font that can be easily recognized by a computer. Any document, form numbers, or alphanumeric text such as IBAN (International Bank Account Numbers), can be quickly scanned with the help of OCR software.