


Mobile Boarding Pass Scanning
Make it easier for passengers to check-in, drop bags and access lounges & Wi-Fi.

Enhance Passenger Experience with Mobile Scanning
Simplify the passenger experience as they move through the airport. Turn every smartphone into a mobile boarding pass scanner. Enable weary travellers to enter lounges without waiting in long concierge lines. Give time-strapped passengers friction-free access to Wi-Fi. Make airport workers more efficient and boost their job satisfaction by ensuring consistent, first-time scanning of boarding passes, even when they are angled, crumpled and blurred.
Embed IATA boarding pass scanning quickly and easily into existing native mobile, web app and desktop apps with just a few lines of code. Try the demo or download the fully supported 30-day trial.
Turn Smartphones into Air Travel Scanners
Mobile Check-in and Bag Drop
Simplify flight check-in and bag drop-off with fast mobile boarding pass scanning. Reduce the stress for passengers and make life easier for airline staff.
Fast Capture of IATA 2D barcodes
Accurate capture of of all common IATA BCBP barcodes including QR codes, PDF417, Aztec and Data Matrix codes.
Secure
Scanning is purely on the client device so all data stays secure and on-premise. Dynamsoft is ISO27001 certified.
Embed with just a few lines of code
Build smartphone scanning into your mobile, web or desktop airline operations apps.

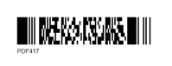



Scan Blurred & Wrinkled Passes Every Time
The realities of air travel means crumpled and folded boarding passes presented in a rush at awkward angles. You need a scanning solution that’s designed for these challenging conditions. We use multi-threading and pre-processing to deliver exceptional accuracy from low-quality images like these:

Crumpled & folded boarding passes
Barcodes often get wrinkled or folded making it tricky to scan successfully.

Poor lighting & glare
Low light is often an issue. Equally, glare from other screens or lights can make barcodes difficult to read.

Awkward angles & blurring
Passengers grappling with multiple bags or rushing may hold the boarding pass at a difficult angle.
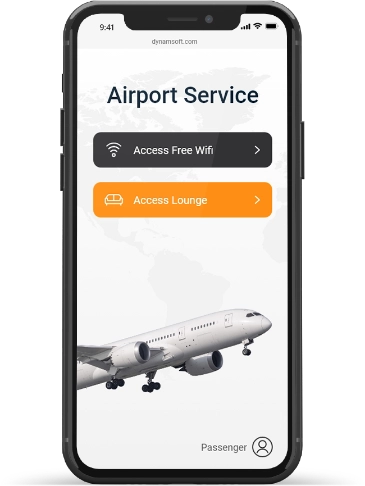
Faster Entry to Airport Lounges
Reduce the lines at passenger lounges and boost your passenger experience. Embed boarding pass scanning into your lounge app or website in less than a day. Offer flexible scanning options for guests.
Scan printed boarding passes
Some passengers prefer paper. Ensure reliable scanning whether they are printed at the airport or at home.
Read mobile boarding passes
Scan direct from mobile boarding passes.
Scan MRZ passports
Our MRZ Passport Reader means you can provide additional options.
Native Mobile
Capture

Web APP
Capture
Desktop App
Capture
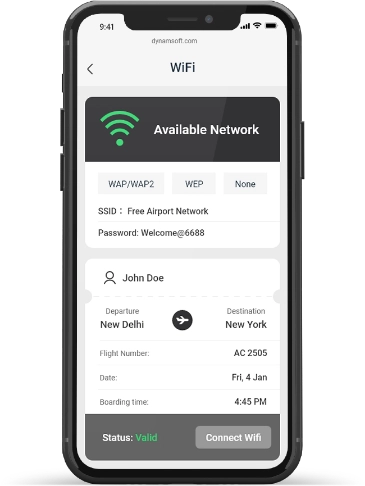
Frictionless Access to Wi-Fi
Air travel is stressful enough. Give passengers a friction-free way to access airport Wi-Fi when they are in a hurry.
Embed scanning into your Wi-Fi web app
Embed scanning quickly and efficiently into your browser based app. Blend it seamlessly into your UX and branding.
Full technical support throughout your trial
We want your evaluation to be successful. We’ll provide technical support to help you optimize the SDKs for your specific use case challenges.
Flexible licensing options
We will work with you to find a licensing model that makes sense for your business model.