


Escáner de Documentos — TWAIN, WIA, ISIS o SANE
La funcionalidad de escaneo de documentos es un componente crítico para un desarrollador de software que construye un sitio web, sistema de gestión de contenido o sistema de automatización de oficina. Hay varios controladores de escaneo diferentes en el mercado:
Naturalmente, es posible que estés confundido acerca de cuál es la mejor solución para ti. TWAIN, WIA, ISIS y SANE son controladores de escaneo que admiten la adquisición de imágenes físicas desde escáneres y el almacenamiento de las imágenes digitales en una computadora. Aunque intentan lograr básicamente la misma tarea, una búsqueda de popularidad muestra que TWAIN lidera el juego.
Estos cuatro controladores de escaneo de documentos tienen algunas funcionalidades y compatibilidades de escáner diferentes, lo que los hace adecuados para diferentes situaciones. Veamos cada uno de ellos uno por uno.
¿Qué es el escaneo TWAIN?

TWAIN es un protocolo de escaneo que inicialmente se utilizaba para los sistemas operativos Microsoft Windows y Apple Macintosh, y agregó soporte para Linux/Unix a partir de la versión 2.0. El primer lanzamiento fue en 1992. Fue diseñado como una interfaz entre el software de procesamiento de imágenes y los escáneres o cámaras digitales.
¿Dónde puedo conseguir un escáner compatible con TWAIN?
TWAIN es el protocolo más utilizado y el estándar en escáneres de documentos. En particular, estos fabricantes de escáneres son miembros del grupo de trabajo TWAIN: Fujitsu Computer Products of America, Kodak Alaris, Epson America, HP y Visioneer.
Aquí tienes una lista de controladores certificados por TWAIN: http://resource.twain.org/twain-certified-drivers/
En la mayoría de los casos, los usuarios deberían poder obtener un controlador TWAIN gratuito o encontrar fácilmente uno (desde el sitio web del fabricante).

El software tiene tres elementos clave:
- La Aplicación
- El Administrador de Origen
- El Origen de Datos
La interfaz del Administrador de Origen proporcionada por TWAIN permite que tu aplicación controle los orígenes de datos, como escáneres y cámaras digitales, y adquiera imágenes, como se muestra en la figura a continuación. 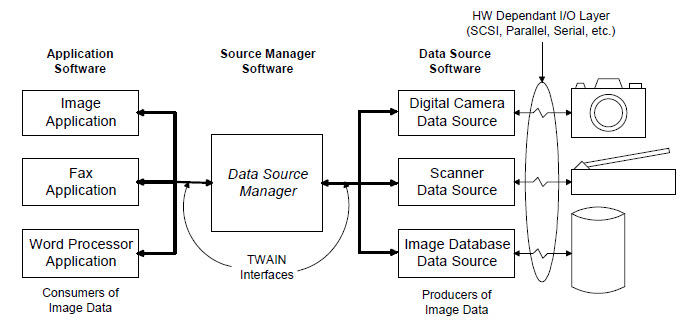
Aunque casi todos los escáneres contienen un controlador TWAIN que cumple con el estándar TWAIN, la implementación de cada controlador de escáner TWAIN puede variar ligeramente en términos de diálogo de configuración del escáner, capacidades personalizadas y otras características. Es bueno si deseas utilizar funciones específicas de un modelo de escáner en particular, pero si deseas que el comportamiento de escaneo de tu aplicación sea consistente en diferentes escáneres, debes tener cuidado con el código personalizado.
El estándar TWAIN está evolucionando hacia la próxima generación, llamada TWAIN direct. El grupo de trabajo TWAIN, del cual Dynamsoft es miembro asociado, afirma que con TWAIN direct ya no será necesario utilizar controladores específicos del fabricante. La aplicación podrá comunicarse directamente con los dispositivos de escaneo. Lo mejor de TWAIN direct está por venir.
¿Qué es WIA?
WIA (Windows Image Acquisition), introducido por Microsoft desde Windows Me, es la plataforma de controladores suministrada con el sistema operativo Windows, incluyendo Windows 7, Windows 8, etc. Permite a las aplicaciones adquirir imágenes de todo tipo de cámaras digitales y escáneres. ¿Suena muy similar a TWAIN, verdad?
Tanto TWAIN como WIA pueden funcionar con escáneres y cámaras siempre que el controlador esté instalado. En general, si tu aplicación va a interactuar principalmente con escáneres, especialmente si se necesitan admitir escáneres antiguos, se recomienda utilizar TWAIN. Para cámaras, WIA ofrece un mejor soporte. Sin embargo, a veces las aplicaciones basadas en TWAIN pueden comunicarse con dispositivos WIA, como escáneres o cámaras, a través de la “capa de compatibilidad de TWAIN”.
Existen otras diferencias entre TWAIN y WIA. TWAIN tiene tres modos de transferencia (nativo, memoria, archivo), mientras que WIA solo tiene dos (memoria, archivo). TWAIN permite a los fabricantes de dispositivos crear una interfaz de usuario personalizada para cada controlador. WIA utiliza una interfaz de usuario simplificada para todos los dispositivos, basada en un modelo de objeto de scripting. Si solo necesitas funciones básicas de escaneo, WIA es suficiente. Si necesitas utilizar características más sofisticadas de un escáner, como opciones diferentes para cada página al escanear en modo dúplex, TWAIN debería ser tu elección.
¿Qué es ISIS?
ISIS (Image and Scanner Interface Specification) es una interfaz de escáner propietaria desarrollada por Pixel Translations en 1990 (hoy en día: EMC Captiva).
A diferencia de TWAIN, que es producido por una organización sin fines de lucro, ISIS no es gratuito. Los fabricantes de escáneres deben pagar una tarifa de regalías para poder utilizar el controlador ISIS. Aunque originalmente ISIS estaba destinado a entornos de producción (mayor volumen, soporte de características avanzadas de escáneres de gama alta), el alto costo está alejando a los fabricantes. Como resultado, ISIS no es popular en las empresas.
Además, a pesar de la reputación de ISIS en cuanto a rendimiento, muchos desarrolladores también han afirmado que no se identifica ninguna ventaja técnica obvia al comparar ISIS con TWAIN.
¿Qué es SANE?

SANE (Scanner Access Now Easy) es una interfaz de programación de aplicaciones (API) comúnmente utilizada en UNIX (incluyendo GNU/Linux).
SANE es un proyecto de código abierto. Puedes descargar su código fuente (última versión 1.0.24) en http://www.sane-project.org/source.html.
A diferencia de TWAIN, SANE separa la interfaz de usuario (frontend) del controlador del dispositivo (backend). El controlador de SANE solo proporciona una interfaz backend, con el hardware y el uso de una serie de “opciones” para controlar cada escaneo. Un ejemplo de una opción para definir el área de escaneo es el siguiente, 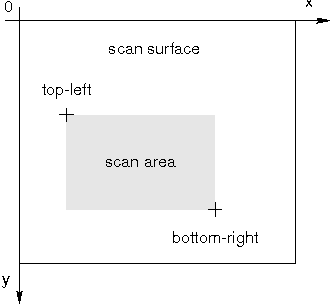
Esta implementación separada hace que SANE sea perfectamente adecuado para un escenario de escaneo en red, donde tienes todas las computadoras conectadas en una LAN y los escáneres conectados a solo una o dos computadoras como escáneres compartidos. Además, al no estar ligado a una GUI específica, como TWAIN lo está con Win32 o la API de Mac, SANE es más fácil de implementar con una interfaz basada en línea de comandos. Por otro lado, SANE cuenta con algunas GUI, como XSane, phpSANE, etc., que puedes utilizar si es necesario. O puedes personalizar una GUI específicamente para un escáner.
¿Qué es eSCL?
eSCL es un protocolo de escaneo sin controlador promovido por Apple. eSCL permite el escaneo a través de dispositivos conectados por Ethernet, inalámbricos y USB. Basado en XML y HTTP, eSCL es un protocolo muy ligero y adecuado para la expansión desde escritorio a plataformas móviles. Puedes encontrar su especificación completa en Mopria.org. A medida que aumenta la demanda de escaneo inalámbrico, un número creciente de escáneres está soportando el protocolo eSCL.
El protocolo eSCL es amigable con dispositivos móviles como smartphones. Dynamsoft ha desarrollado una aplicación específica llamada Dynamsoft Service para dispositivos Android, de modo que los dispositivos Android puedan conectarse directamente a escáneres eSCL para escanear. Sin embargo, en comparación con protocolos tradicionales como TWAIN, eSCL no es la mejor opción para trabajos de escaneo de alto volumen, ya que la capacidad de escaneo del protocolo eSCL no es tan buena como la de TWAIN.
Conclusión
¿Ya tienes una idea y has tomado una decisión? A continuación, se presenta una tabla comparativa de estos 4 controladores que resume lo mencionado anteriormente.
TWAIN | WIA | ISIS | SANE | eSCL | |
| Funcionalidad de Escaneo | ★★★★ | ★★★ | ★★★★★ | ★★★★ | ★★★ |
| Soporte para cámaras digitales | ★★★★ | ★★★★★ | ★★ | ★ | ★ |
| Soporte de SO | Windows, macOS, Linux/Unix | Windows | Windows | Linux/Unix | Windows, macOS, Linux/Unix, iOS, Android |
| Participación en el mercado de escáneres | ★★★★★ | ★★★★ | ★★ | ★★ | ★★ |
| Participación en el mercado de aplicaciones | ★★★★★ | ★★★★ | ★★ | ★★ | ★★ |
| Precio | Gratis | Gratis | Costoso | Gratis (código abierto) | Gratis (código abierto) |
Los controladores TWAIN son superiores en la mayoría de los casos, ya que brindan la máxima compatibilidad con escáneres y también la libertad para personalizar el escaneo según el modelo del escáner. Si estás desarrollando una aplicación de escaneo sencilla, WIA también puede ser adecuado.
ISIS may only be suitable given a specific requirement. SANE provides optimal support across network scanning and for systems where there is no Windows system.
