


SDK Overview: Modules and Main APIs
This page provides an overview of the various modules and highlights the most essential APIs that form the backbone of Dynamsoft Capture Vision SDKs.
Modules Summary
DynamsoftCaptureVisionBundle is a bundle package that includes all libraries of Dynamsoft Capture Vision (DCV) architecture. The DCV libraries work together to achieve barcode reading, MRZ recognizing, document scanning and other image processing features. The hierarchical structure diagram below illustrates the various modules of the DCV SDKs (with modules at the top depending on those below).
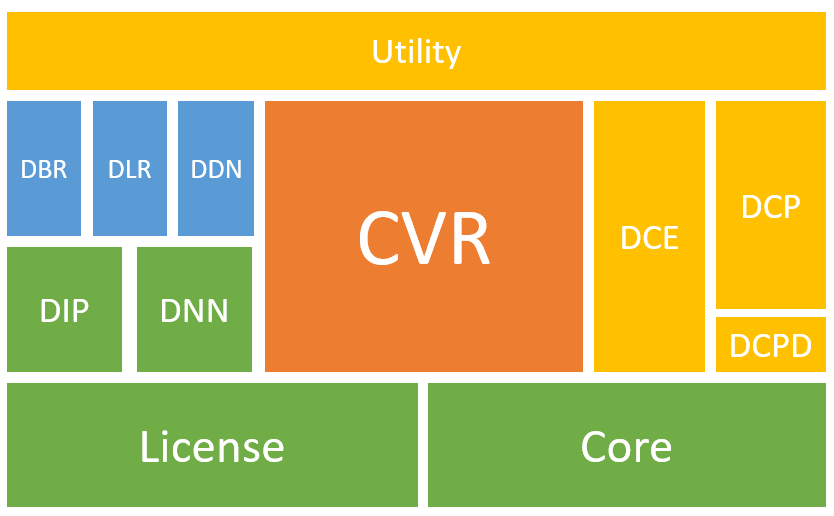
Modules hierarchical of the DCV SDK
The table below describes details the functionalities of these modules:
| File | Description |
|---|---|
DynamsoftCaptureVisionRouter.aar |
The Dynamsoft Capture Vision Router module is the cornerstone of the Dynamsoft Capture Vision (DCV) architecture. It focuses on coordinating batch image processing and provides APIs for setting up image sources and result receivers, configuring workflows with parameters, and controlling processes. |
DynamsoftBarcodeReader.aar(DBR) |
The Dynamsoft Barcode Reader module recognizes and decodes multiple barcode formats such as QR codes, Code 39, Code 128, and Data Matrix, among many others. |
DynamsoftDocumentNormalizer.aar(DBR) |
The Dynamsoft Document Normalizer module extracts structural information from document images, including document boundaries, shadow areas, and text areas. It uses this information to generate normalized document images through processes such as deskewing, shadow removal, and distortion correction. |
DynamsoftLabelRecognizer.aar (DLR) |
The Dynamsoft Label Recognizer module identifies and recognizes text labels such as passport MRZs, ID cards, and VIN numbers. |
DynamsoftCore.aar |
The Dynamsoft Core module lays the foundation for Dynamsoft SDKs based on the DCV (Dynamsoft Capture Vision) architecture. It encapsulates the basic classes, interfaces, and enumerations shared by these SDKs. |
DynamsoftImageProcessing.aar |
The Dynamsoft Image Processing module facilitates digital image processing and supports operations for other modules, including the Barcode Reader, Label Recognizer, and Document Normalizer. |
DynamsoftNeuralNetwork.aar |
The Dynamsoft Neural Network module allows SDKs compliant with the DCV (Dynamsoft Capture Vision) architecture to leverage the power of deep learning when processing digital images. |
DynamsoftLicense.aar |
The Dynamsoft License module manages the licensing aspects of Dynamsoft SDKs based on the DCV (Dynamsoft Capture Vision) architecture. |
DynamsoftCameraEnhancer.aar |
The Dynamsoft Camera Enhancer (DCE) module controls the camera, transforming it into an image source for the DCV (Dynamsoft Capture Vision) architecture through ISA implementation. It also enhances image quality during acquisition and provides basic viewers for user interaction. |
DynamsoftUtility.aar |
The Dynamsoft Utility module defines auxiliary classes, including the ImageManager, and implementations of the CRF (Captured Result Filter) and ISA (Image Source Adapter). These are shared by all Dynamsoft SDKs based on the DCV (Dynamsoft Capture Vision) architecture. |
DynamsoftCodeParser.aar |
The Dynamsoft Code Parser module converts data strings, typically encrypted in barcodes and machine-readable zones, into human-readable information. |
DynamsoftCodeParserDedicator.aar |
The Dynamsoft Code Parser Dedicator module provides auxiliary functionality to enhance and extend the capabilities of DCP module. |
Main APIs
Capture Vision Router
The main class CaptureVisionRouter acts as the SDK entry point and provides the following essential APIs:
Image Source Adapter
The ImageSourceAdapter class is an abstract class representing an adapter for image sources, providing a framework for fetching, buffering, and managing images from various sources. It serves as the input for the CaptureVisionRouter. You can either use the typical implementations of ImageSourceAdapter or implement your own.
Class CameraEnhancer is one of the typical implementations of ImageSourceAdapter. It is a class that not only implements the video frame obtaining APIs but also enable you to improve the video quality by adjusting the camera settings.
Captured Result Receiver
Implement the callback methods of CapturedResultReceiver to receive the corresponding results you required. The callbacks are triggered when the processing of an image/vide frame is finished or timeout.
Barcode Decoding
Callback methods that are related to barcode decoding:
onDecodedBarcodesReceived: The callback of barcode decoding. The result you received in the callback method is aDecodedBarcodesResultobject, which contains all the decoded barcodes from the processed image.
Related APIs:
DecodedBarcodesResult: All barcodes that decoded from the processed image.BarcodeResultItem: The barcode decoding result of a single barcode.
Document Scanning
Callback methods that are related to document scanning:
onDetectedQuadsReceived: The callback of document boundary detection. The result you received in the callback method is aDetectedQuadResultobject, which contains all the detected quads from the processed image.onNormalizedImagesReceived: The callback of image normalization. The result you received in the callback method is aNormalizedImagesResultobject, which contains all the normalized images from the processed image.
Related APIs:
DetectedQuadResult: All quads that detected from the processed image.DetectedQuadResultItem: The boundary detection result of a single document page.NormalizedImagesResult: All normalized images that deskewed from the processed image.NormalizedImageResultItem: The deskewing result of a single document page.
MRZ Scanning
Callback methods that are related to MRZ scanning:
onParsedResultsReceived: The callback of content parsing. The result you received in the callback method is aParsedResultobject, which contains all the parsed results from the processed image.onRecognizedTextLinesReceived: The callback of text recognition. The result you received in the callback method is aRecognizedTextLinesResultobject, which contains all the original MRZ text of the processed image.
Related APIs:
ParsedResult: All parsed results that captured from the processed image.ParsedResultItem: The parsing result of a single parsable content.RecognizedTextLinesResult: All text lines that recognized from the processed image.TextLineResultItem: The text recognition result of a single text line.
Camera View
CameraView is a view class that design for visualizing the real time video streaming and the barcode decoding result. If the CameraEnhancer is set as the input of your CVR, the decoded barcodes will be highlighted automatically on the CameraView.