
The upcoming Spring 5 Framework has a strong focus on Reactive Programming, allowing us to write both servers and clients using this paradigm. The Spring 5 implementation uses the popular Project Reactor as a base.
This article will be an introduction to writing both Reactive Clients and Servers using the new tools available in version 5 of the framework.
Reactive Programming has become very popular of late, and with good reason.
Simply put, it’s a non-blocking alternative to traditional programming solutions, working entirely with event driven data streams and functional programming concepts to manipulate these streams. It is a way to allow data changes in one part of the system to automatically update other parts of the system and to do so with minimal cost to ourselves.
As reactive streams are non-blocking, the rest of the application doesn’t have to be waiting while the data is being processed. This helps to allow reactive servers to scale significantly further beyond more traditional implementations because the worker threads in the application are not tied up waiting for other resources – they’re typically free to handle more incoming requests.
This is best described with a real example. We are going to load some data from the database, manipulate it and then return it to the caller.
In a traditional imperative system, this would be done be retrieving a list, and iterating over it:
List<User> users = userDao.getUsers();
List<String> names = new ArrayList<String>();
for (int i = 0; i < users.size(); ++i) {
names.add(users.get(i).getName());
}
In a functional system, where we have a stream of values over a collection, we could instead do this:
List<String> names = userDao.getUsers().stream() .map(user -> user.getName()) .collect(Collectors.toList());
This is a lot simpler to understand, but still slightly awkward. Especially if our database is busy with other queries and is returning slowly – our thread will be blocked waiting for the data to come back before we can do anything with the data.
In a reactive model, we can do something like this:
Flux<String> names = reactiveUserDao.getUsers() .map(user -> user.getName());
At first glance, this looks very similar to before. However, because this is reactive the entire command is non-blocking so our main thread is not tied up in the operation. Additionally, if the caller is also reactive, then the non-blocking nature propagates all the way.
For example, if this was a reactive web server then the thread handling the request will be immediately free to handle other requests, and as the data appears from the database – it will be sent down to the client automatically.
The real key that makes Reactive programming a significant improvement over more traditional code is backpressure. This is the concept by which the producing end of the stream understands how much data the consuming end is capable of receiving, and is able to adjust its throughput accordingly.
In a simple scenario, there’s no need for backpressure, because the consuming end can receive data as fast as it can be produced. However, in the situation where the producing end is performing an expensive operation – such as reading data out of a database – it might become important to only perform these operations when the consuming end is ready for the data.
Similarly, in a situation where the consuming end is itself limited – such as streaming data over a limited bandwidth network connection – backpressure can help ensure that no more work than is absolutely necessary is performed.
Of course, this can only help temporarily, and there’s a point where the application won’t be able to deal with the pressure and will fail. At that point, it’s critical to have a solution in place that can actually help understand what happened.
For example, with our earlier example – if the client connecting to our handler is running slow, then it can not consume data as quickly. This will cause backpressure down the reactive stream, which in turn will indicate to the database layer to stop sending the data as quickly.
This can cause a slow client to reduce the load on the database server, all the way through the application layer, which, in turn, can allow the database server to handle requests for other clients, making the entire system more efficient.
Project Reactor is built around two core types – Mono<T> and Flux<T>. These are both data streams, but a Mono<T> is a stream of at most 1 value, whereas a Flux<T> is a stream of potentially infinite values.
The distinction between these two types is relatively small. Some operations only make sense to be performed on one or the other, and the semantics behind them are different. If an operation can only have a single value that can not change it should be a Mono, and not a Flux.
These streams operate under a Deferred Pull/Push model.
Requesting data from a stream is done by subscribing to that stream. Naturally, you have a few options here.
If you simply wish to get a single piece of data out of the stream to use in a more traditional way – then you can block on the stream until you get the value. For a Mono, there’s a single block() call that will return as soon as the Mono has resolved a value. When working with a Flux – you can use the blockFirst() and blockLast() APIs instead, to get either the first or last value from the stream.
Blocking defeats the purpose of using reactive streams though. Instead, we want to be able to add a handler that will be triggered every time some data appears and allow the reactive stream to control when it gets called.
This is done with the subscribe() call instead – which takes a Consumer implemented as a lambda; this will be called for every data element that reaches it:
reactiveUserDao.getUsers()
.map(user -> user.getName())
.subscribe(name -> System.out.println("Seen name: " + name));
This will print out every name that we get from the DAO. And, if the DAO is running slowly, the names will be printed out as quickly as the database can manage rather than waiting for the entire list to be produced first.
At a first glance, this seems very similar to Java 8 Streams. The difference is in some of the details, but these details are quite important.
Java 8 Streams are really nothing more than a way of providing functional programming techniques to Java collections. Essentially they act as iterators over a Java 8 Collection that can then manipulate the values and produce a new collection. They’re not designed to act as unreliable streams of data, and they do not act well in that situation.
Reactive Programming Streams are instead designed to have some arbitrary input source that could produce a potentially infinite number of values, over an unknown time period, and will handle this well.
They’re also designed to be connected to a non-blocking source at one end, and a non-blocking sink at the other end, allowing data to flow from one to the other, but this is by no means a necessity. No point in the pipeline is concerned with what happens elsewhere in that pipeline.
Interestingly, Project Reactor streams are also reusable, which is a significant difference from Java 8 Streams. For example, the following works fine:
Flux<Integer> j = Flux.just(1, 2, 3, 4, 5); j.map(i -> i * 10) .subscribe(System.out::println); j.map(i -> i + 5) .subscribe(System.out::println);
Whereas this will throw an IllegalStateException error at runtime:
Stream<Integer> j = Arrays.asList(1, 2, 3, 4, 5).stream(); j.map(i -> i * 10) .forEach(System.out::println); j.map(i -> i + 5) .forEach(System.out::println);
And, of course, streaming has been used to improve the performance of a system in many other scenarios, so it’s a well-established practice by this point.
Spring 5 introduces the ability to use reactive programming in our applications – both on the server and client layer. Earlier versions of Spring 5 called this spring-reactive, but as of Spring 5.0.0.M5 this has been renamed Spring WebFlux.
Adding Spring WebFlux to a Spring Boot application is done by adding Spring Boot Starter WebFlux instead of Spring Boot Starter Web:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-webflux</artifactId> <version>2.0.0.M3</version> </dependency>
Or with Gradle:
compile "org.springframework.boot:spring-boot-starter-webflux:2.0.0.M3"
Amongst other things, this will pull in:
Writing a non-blocking, reactive HTTP Client with Spring WebFlux is a case of using the new WebClient class instead of the RestTemplate class. This class allows us to make a request to the server, and apply transformations and actions to the response when it eventually comes back, all without blocking any other operations in our code.
To start with we need a WebClient instance. At its simplest we just create a new WebClient that can access any URL:
WebClient.create()
Alternatively, it’s recommended to create a WebClient for a specific API and access URLs underneath a base URL:
WebClient.create("https://deckofcardsapi.com/api/deck")
We can now use this to actually make an HTTP Call to the API:
WebClient.create("https://deckofcardsapi.com/api/deck")
.get()
.uri("/new/shuffle?deck_count=1")
.accept(MediaType.APPLICATION_JSON)
.exchange()
The majority of this deals with setting up the request that we are going to make. It is to be a GET call to /new/shuffle?deck_count=1 underneath the base URL we are calling, and we would like the response in JSON format.
The exchange() method will immediately return a Mono<ClientResponse>, which will eventually represent the response from the server. The eventual nature of this is important. We can execute this, then go and do some other processing, confident that it will be executing in the background for us.
We can then add some extra behaviour to this for when the value does come back.
For example, the above returns a JSON blob that looks similar to the following:
{
"success": true,
"deck_id": "3p40paa87x90",
"shuffled": true,
"remaining": 52
}
We’re only interested in the “deck_id” value, so let’s transform our response when it comes back:
WebClient.create("https://deckofcardsapi.com/api/deck")
.get()
.uri("/new/shuffle/?deck_count=1")
.accept(MediaType.APPLICATION_JSON)
.exchange()
.flatMap(response -> response.bodyToMono(Map.class))
.map(response -> response.get("deck_id"))
The flatMap() call here is used to extract and convert the body of the response – using the standard Jackson ObjectMapper functionality. The map() call is then used as we’d expect, to convert one value into another one.
What we’ve got here will look remarkably similar to the Java 8 Streams API, because it’s modelled along similar ideas. It all looks synchronous and is easy to understand. However, the lambda passed to the flatMap() call will not execute until the HTTP Response comes back, and the likewise the map() handler will not execute until the JSON has been parsed into a Map object.
This is most useful when we want to do several things together that depend on each other.
For example, the above can be extended to actually draw a card from the shuffled deck as follows:
WebClient webClient = WebClient.create("https://deckofcardsapi.com/api/deck");
Mono<Map> card = webClient.get()
.uri("/new/shuffle/?deck_count=1")
.accept(MediaType.APPLICATION_JSON)
.exchange()
.flatMap(response -> response.bodyToMono(Map.class))
.map(response -> response.get("deck_id"))
.flatMap(deckId ->
webClient.get()
.uri("/{deckId}/draw", Collections.singletonMap("deckId", deckId))
.accept(MediaType.APPLICATION_JSON)
.exchange()
.flatMap(response -> response.bodyToMono(Map.class))
)
This entire set of calls is completely non-blocking. Once executed, the processing will immediately continue, and eventually, we can use the card variable to see what card was drawn.
This means that the two HTTP calls are happening in the background and our code needs do nothing to manage that fact.
So far, we’ve been doing Reactive programming with a single response. But, where this paradigm can be even more useful is with WebSockets. In this case, we can get an arbitrary number of messages coming back to us that we need to handle as and when they appear.
The implementation can be done just as easily using the WebSocketClient interface that Spring WebFlux provides. Unfortunately, to use it, we need to know which concrete type we’re using – there is no helpful builder at present – but by default, the ReactorNettyWebSocketClient implementation is available and ready to use.
We can write a simple client that will call the WebSocket Echo Service and log the messages as follows:
WebSocketClient webSocketClient = new ReactorNettyWebSocketClient();
webSocketClient.execute(new URI("wss://echo.websocket.org"), session ->
session.send(input.map(session::textMessage))
.thenMany(session
.receive()
.map(WebSocketMessage::getPayloadAsText)
.log())
.then())
The processing in place of the log() call can be as complex as is necessary, and it will be automatically called whenever a new message appears on the WebSocket connection. And, once again, the entire code is entirely non-blocking.
As you’re starting to see, the reactive paradigm allows you to write some powerful new functionality in a way that just wasn’t possible before.
However, the most exciting development here is around writing reactive server-side applications. This allows us to write logic that is entirely non-blocking, which in turn means that it can scale significantly higher than a more traditional architecture is able to, and with relative ease.
Note that we do need to run this on a suitable web server. By default, Spring Boot WebFlux will use the Netty server – which supports everything we need. If we need to run inside an existing container infrastructure, we can do so as long as that supports Servlets 3.1.0 – for example, Tomcat 8.x.
Writing a Spring WebFlux server-side logic is virtually the same as writing typical, Spring MVC logic. We can actually use exactly the same annotations for defining our controllers, as long as we return Reactor types from our controller methods instead. For example:
Here’s a quick example of what that might look like:
@RestController
public class PostController {
private final PostRepository repository;
public PostController(PostRepository repository) {
this.repository = repository;
}
@GetMapping("/posts")
Flux<Post> list() {
return this.repository.findAll();
}
@GetMapping("/posts/{id}")
Mono<Post> findById(@PathVariable String id) {
return this.repository.findOne(id);
}
}
Here we’re using a data repository that works in a reactive way, provided by Spring Data. We then return our Flux or Mono types directly, and Spring WebFlux does the rest of the work for us.
This is essentially streaming the data directly from our data store down to the HTTP Client with very little involvement from our software. We can add additional processing to the elements as always, using the standard functional methods – e.g. filter(), map():
@GetMapping("/posts/titles")
Mono<String> getPostTitles() {
return this.repository.findAll()
.map(post -> post.getTitle());
}
Conversely, we can write reactive controllers that will read data from the client and process it as it comes in.
The huge benefits here are that the entire server is acting in an entirely reactive way. A request comes in from the client, the server makes a call to the database and passes the data back.
In a traditional server, the data would be loaded entirely from the database to the server before any of it was sent back from the server to the client – which can be slow. Here’s what that would look like:
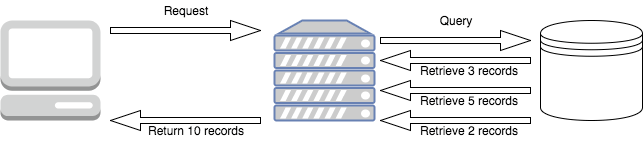
In a reactive server, the data will be passed to the client the instant it’s available from the server, and as it flows out of the server it will flow through our application and down to the client:
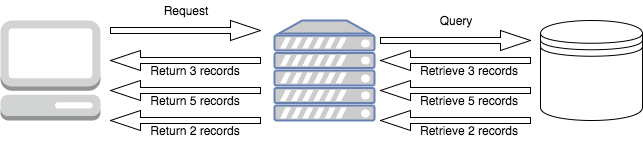
This means that the client waits less for the first data to appear and that the server doesn’t have to store data from the database until it’s all available. Records are processed immediately on being retrieved from the data store and passed on.
Naturally, these characteristics can lead to small improvements in some scenarios, and to very significant savings in others.
Having just seen how we can write entirely reactive web server logic, we’ll typically still hit a blocking layer when we interact with our database. Spring addresses this as well, with the new reactive extensions to the Spring Data layer.
At present this only works with a small number of NoSQL data stores – primarily MongoDB – as the underlying data store needs native Asynchronous client support. Right now, it’s unclear if JDBC support will be coming or not.
Supporting reactive MongoDB in our application can be done by using the MongoDB Reactive Streams driver instead of the standard one. This is done by using the following dependency:
<dependency> <groupId>org.mongodb</groupId> <artifactId>mongodb-driver-reactivestreams</artifactId> <version>1.5.0</version> </dependency>
Reactive data repositories are written by implementing the ReactiveCrudRepository interface instead of the normal CrudRepository, and by having our interface methods return the reactive Mono and Flux types:
public interface PostRepository extends ReactiveCrudRepository<Post, String> {
Flux<Post> findByAuthor(String author);
}
This gives us the default methods that we already know from Spring Data:
As you can see, these can immediately be connected to our reactive controller methods to stream data from the database to the web client with minimal effort.
Enabling support for Reactive MongoDB Repositories within Spring Data is done using the @EnableReactiveMongoRepositories annotation instead of the normal @EnableMongoRepositories.
If Spring Data is not a good fit for our application, there’s also a new Reactive version of the MongoOperations interface – called ReactiveMongoOperations – that can be used for database access instead. This acts very similarly to the standard MongoOperations but produces and consumes reactive types.
The standard implementation of this is the ReactiveMongoTemplate class that is ready to use and will be provided automatically by the Spring Boot container with no extra work, in exactly the same way as the MongoTemplate class for non-reactive access.
Let’s have a look at exactly how this works and query our data store using this to get all posts with a particular title:
Flux<Post> posts = mongoTemplate.find(
new Query(Criteria.where("title").is("Tackling Reactive Programming in Spring 5")),
Post.class,
"posts").
This again returns a Flux type – so it then can be connected all the way back to our web server handler for an entirely non-blocking request from the client through to the database. And again, we’re able to do any processing on the stream as it’s being processed.
Reactive Programming is clearly an interesting approach to developing web applications today. hugely popular at the moment, giving the ability to write very simple applications that are easy to maintain and scale incredibly well.
Naturally, it doesn’t fit all scenarios – no surprise there. But, where it is a good fit, it can unlock performance that’s simply not possible with a typical architecture, and can really change the characteristics of the system.
And, with Spring 5, we now have the tools to write simple applications that are easy to maintain and scale incredibly well.
Stackify’s tools, Prefix and Retrace, support Java applications for continuous application improvement.
Stackify's APM tools are used by thousands of .NET, Java, PHP, Node.js, Python, & Ruby developers all over the world.
Explore Retrace's product features to learn more.
If you would like to be a guest contributor to the Stackify blog please reach out to [email protected]








